Case Study 2: COMPAS
Contents
Case Study 2: COMPAS#
A few years ago, a company named Northpointe made a machine learning system to help judges decide how to rule on parole. The name of this system was COMPAS (they are into directions, I guess). The idea of the model was to try to predict how likely it would be for someone leaving jail to recommit a crime. Committing a crime after serving time in prison is called “recidivism.” Their model was trying to predict someone’s risk of recidivating after they leave jail from the answers to a quiz they filled out. The questionnaire asked questions about their identity, where they lived, what their job was, etc.
ProPublica (a non-profit newsroom) analyzed the results of COMPAS scores and concluded that the system was biased against people of color. In particular, they found that the system was more likely to predict a higher recidivism risk for black people than white people. Northpointe countered ProPublica’s findings by claiming that their scores were accurate in the sense that if they predicted a score of 9 for anyone (regardless of race), there was a 90% chance they would recidivate.
So the question then is: Which one of these groups is right, and is it ethical to use this system to determine who gets parole? Surprisingly, it turns out that both ProPublica and Northpointe’s arguments are backed up by the data.
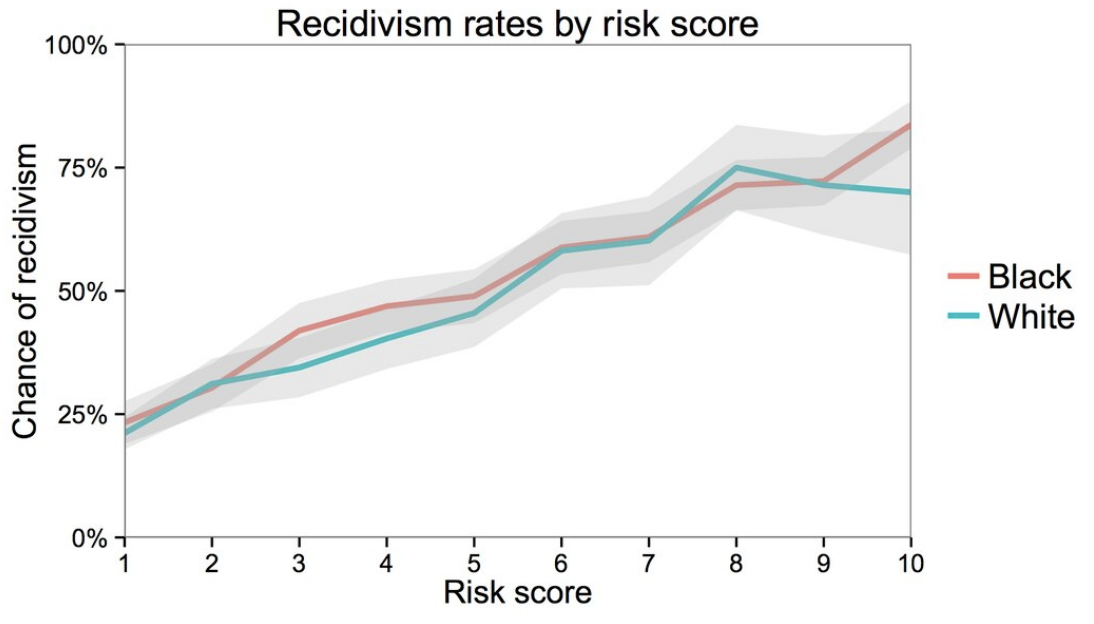
Northpointe’s argument is backed up by the following graph. The x-axis shows the predicted risk score (scaled from 1-10, where a higher is more likely to recidivate). The y-axis shows the actual recidivism rate for those people after they did leave jail. The fact that these lines are close to the line \(y=x\) demonstrates Northpointe’s point. So of the people that they predict a risk score of 0.8, about 80% of the time they recidivate. Additionally, when separated as accuracies for black and white people, you see that the lines are mostly the same (the gray region is a confidence interval to capture uncertainty in the estimate).
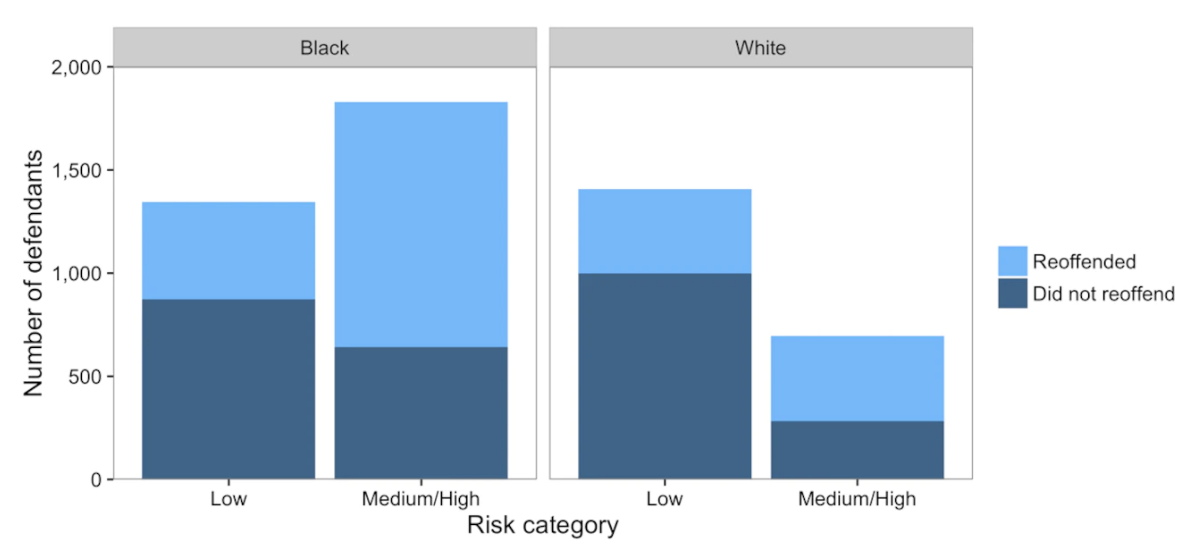
ProPublica’s point is backed up by the following chart. This chart separates the data into black/white people and then within those groups breaks the people up into low and medium/high risk and shows the count of each group. The risk group comes from whether or not COMPAS predicted a small, medium, or high score. The coloring shows which of the people in each group did re-offend and those that didn’t. ProPublica claims that the percentage of people shaded dark blue (those that ultimately did not re-offend) in each race, a more substantial proportion of black people get labeled as medium/high risk. The conclusion from this claim is that if you would genuinely not recidivate, the system is more likely to give you a higher risk if you’re black. They use this as justification to say this model exhibits racist behavior and that judges shouldn’t use it.
The first thing to ask is, where does this bias come from? Surprisingly, it turns out that race isn’t even a question that Northpoint asked on the questionnaire. This means that the model doesn’t even have race as an input. This doesn’t stop the model though, because it’s able to do many correlations to “discover” someone’s race using other features (like their home address, income level, name, etc.). These features can be correlated with race, so the model is not truly “color-blind.”
I would bet that no one at Northpointe coded up the model to be racist (e.g., IS_RACIST = True ) explicitly. In many cases, models that show biased behavior tend to not do so intentionally on the part of the programmer. Unfortunately, the data we give these models is biased because our society has biases around every corner. Regardless of using a machine learning model or not, your treatment by the criminal justice system is, unfortunately, impacted by your race. If we use data from this biased system, the data itself will obviously be biased. The model can then pick up on these biases and reflects them in their decisions. Just as a simple example, the relative incarceration rate for people of color is much higher than white people. The model picks up on this correlation and then uses it for future judgments, without taking into account the historical or societal causes for that difference.
Fairness in Machine Learning#
Right now, a big open question in machine learning and data science is how to accurately define fairness so that we can ensure that our models are fair. A simple set of rules for a fair COMPAS model might be something like:
Equally accurate in predicting recidivism across subgroups (e.g., race).
Members for different subgroups have the same chance of being wrongfully predicted to recidivate (if you truly would not recidivate, your risk score should be the same regardless of race).
Failure to predict recidivism happens at the same rate across subgroups.
Computer scientists have shown that it’s not possible to satisfy all 3 in most real-world scenarios (unless the groups are exactly the same characteristics). Unfortunately, this is unlikely to happen in the real world as long as we have these current and historical injustices towards subgroups. This essentially means that there is a fundamental tradeoff between accuracy and fairness for real-world applications. A fairer system will need to give up some accuracy by some amount, since the definition of accuracy is conforming to the existing biases in the data. Additionally, different definitions of fairness can contradict each other! There is a lot of research to figure out how to identify the right level of tradeoff and the appropriate use cases for each definition of fairness.
Being biased is easy. How do we fix it?#
So is the COMPAs algorithm racist? In some sense, no, since it’s not a person and has no sentience. But in a sense of thinking about outcomes that it makes, yes, since a person’s race can cause differential impact. As we’ve stated before, this bias sneaks in from the data that we learn from itself, rather than the model. This is in-line with the broader notion of “systematic racism” that, as a society, we have become increasingly aware of in-light of in recent years from experience the injustice of black lives lost tragically lost in interactions with police.
Systematic racism is broad, but it’s important to point out that many systems that enshrine racism, don’t do so with malicious intent. Many systems try to be “color-blind”, but that can sometimes just perpetuate biases that exist in the system. As we mentioned before, the model wasn’t explicitly told about race and was still able to demonstrate biased behavior because it could correlate other features with race. So even if “color-blind” was an ideal (not saying that it is), it’s very difficult to achieve.
One idea is to try to explicitly code race into the model, and make sure you use some mechanism to force the model to be fair concerning race. So in some sense, you could think of using race as a feature to prevent racism. This is a promising approach, but often is illegal to do in the first place! Many laws are in place to prevent people from using race as part of a decision to avoid racist behavior in the first place (e.g, credit scores). In that light, we might need to update these laws to account for the fact that these machine learning systems might need this information to prevent biased outcomes.
Another big approach is to use interpretable models. An interpretable model is one that can explain its decisions. For example, think of the neural network model we learned last week. These models are considered black-boxes because it’s complicated to interpret why they made the decision they did. Compare that to a decision tree, where it’s apparent which decisions led the example down the tree to the ultimate choice. If we have these interpretable models, we can hand-check the model to prevent biased decision making. It turns out that black-box models tend to be more accurate in practice, but lots of research is going into making interpretable models that do well in practice (some of that is happening in the Allen School).
Most importantly, always be looking for bias in your datasets to prevent these models from learning from this bias. This is not easy in practice because bias can sneak in very subtly (as we will see in the next case study), but it is a crucial thing to look out for.
Further Resources#
Fairness in machine learning is a relatively new field. FAccT* Conference .
The Ethical Algorithm by Michael Kearns and Aaron Roth (again)