Recap: Pandas
Recap: Pandas#
Data
You can download the dataset used in this reading here: earthquakes.csv
In Lesson 8, we introduced a new library named pandas . Recall that a library is some code someone else wrote and packaged up for us to use. pandas is a very popular library used by data scientists to process tabular data (i.e. data that comes from a spreadsheet).
In the lecture, we saw the Earthquakes dataset stored in earthquakes.csv . To read that CSV into pandas , we would run the code:
import pandas as pd
df = pd.read_csv('earthquakes.csv')
print(df)
We discussed the notion of the pandas DataFrame having a notion of columns and rows . Each column has a column name that identifies it, while the rows have an index that lets you identify each row.
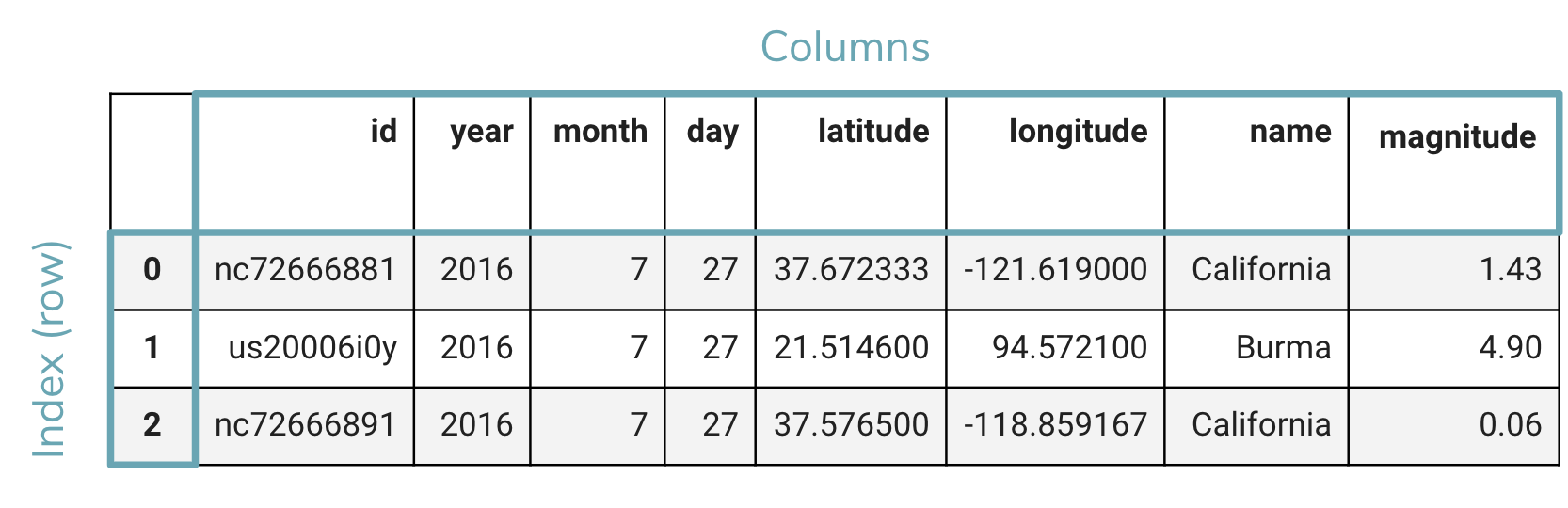
We saw that we can access the data columns from DataFrame using the following syntax:
import pandas as pd
df = pd.read_csv('earthquakes.csv')
print(df['day'])
We also saw we can use a mask to select which subset of the rows we want by filtering our data to rows that have some specific value. For example, if we want to find all the earthquakes in California from 2016, we would write
import pandas as pd
df = pd.read_csv('earthquakes.csv')
print(df[(df['name'] == 'California') & (df['year'] == 2016)])
It can be much more readable to save the sub-parts of the query in variables so your query doesn’t all have to be in one line. For example, you can achieve the same results in a much more readable way like in the following cell.
import pandas as pd
df = pd.read_csv('earthquakes.csv')
is_california = df['name'] == 'California'
is_2016 = df['year'] == 2016
print(df[is_california & is_2016])
Warning
Remember: When you want to filter by multiple conditions using the
&
or
|
operators with
pandas
, you need to put parentheses around the sub-expressions, otherwise it will break. You can avoid needing parentheses by using something more like the second example where you save the masks into variables.
We also learned about the loc property that let us select rows and columns with a more general syntax. You can specify a row indexer and a column indexer to select your data. We saw the following things used as indexers:
A single value (row index for rows, column name for columns)
A list of values or a slice (row index for rows, column names for columns)
A mask
:to select all values
One thing that is also complex about .loc is the type of the value returns depends on the types of the indexers. Recall that a pandas DataFrame is a 2-dimensional structure (rows and columns) while a Series is a single row or single column .
To tell what the return type of a .loc call is, you need to look for the “single value” type of indexer.
If both the row and column indexers are a single value, returns a single value. This will be whatever the value is at the location so its type will be the same as the
dtypeof the column it comes from.If only one of the row and colum indexers is a single value (meaning the other is multiple values), returns a
Series.If neither of the row and column indexers are single values (meaning both are multiple values), returns a
DataFrame.