Machine Learning and Images
Contents
Machine Learning and Images#
In the recap, we mentioned how when we first learned about ML, we talked about it in the context of CSV data where it is easier to define what the features used by the model should be. This doesn’t necessarily have to be the case, features can be generic to be any number you compute from your data!
When working with images, it’s a little less clear how to define these features. Suppose we wanted to train a classifier to tell dog images from cat images. We would somehow need to derive features from the image that would be useful in predicting if the image contains a dog or a cat. Maybe we could try writing code to produce features like LikesPeople, LooksFriendly, FloppyEars from an image, then we could plug that into something like a DecisionTreeClassifier and we would be done!
As you might be able to tell though, it is not clear at all how we could begin to write code to take pixels from an image and compute these high-level features! So instead, we will rethink our approach to let the machine learning algorithm try to learn how to predict the label from the image itself!
There are two very common practices when working with image data for machine learning:
“Vectorize” the image so it is usable by standard machine learning approaches (explained below).
Use a very powerful model class called neural networks to learn high-level concepts from low-level features like pixels (discussed in the next slide).
Vectorizing Images#
The idea here is to “unroll” the image so instead of having 2-dimensions, it only has 1. Pictorially for a very small example image, this looks like the image below.
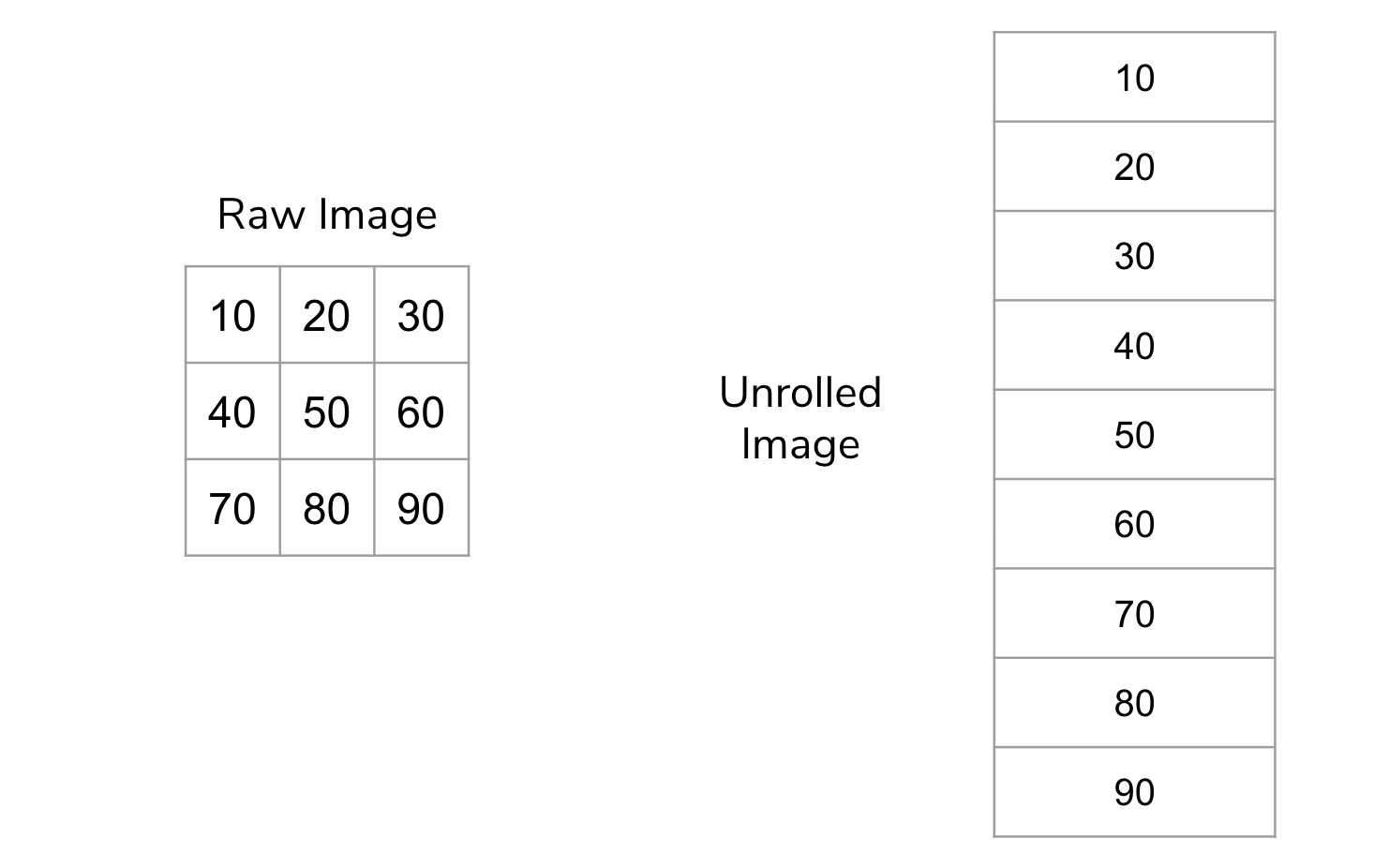
Most machine learning models are generic enough to take any series of features (commonly called a vector from mathematics) and learn a model from them. By unrolling the image, we now have created a feature for every pixel in the image! If you are working with color images, you would unroll the color channels into this long vector too!
You can imagine this will be complicated because there are lots of pixels in even moderately sized images! In our dog.jpg example from Lesson 22, there are almost 500,000 pixel values in the image if you count each color channel separately! That is way more features than we ever used for a model in class!
This will then be a very complex and difficult learning task since there are so many features to work with. This is why we commonly use the second strategy listed above, which is using neural networks. This is explained on the next slide.