Objects and References
Contents
Objects and References#
An object (also sometimes called an instance) in Python is a way of encapsulating state (the data it represents) and behavior (the functions it can perform) in one distinct unit. This is horribly vague because it’s quite a general notion (just like the word “object” in English is hard to describe).
We have used the term object a few times in this course to refer to something like a pandas.DataFrame or the value of f in open('file.txt') as f . These objects are things you can interact with within your programs by calling functions on them (i.e. calling one of their behaviors ) and the output of these functions is determined by the data inside the object (i.e. its state ). The following code cell creates a pandas.DataFrame object and then calls a function to show its state.
import pandas as pd
df = pd.DataFrame({'a': [1,2,3]}) # One column, three rows
print(df.to_string()) # Method to look at all data as a `str`
State and Behavior#
In this example, we think of the DataFrame as having the following states and behaviors.
State
The columns
The index
The actual data in the table
Etc.
Behavior
Methods for providing access to the data
Methods to modify data
Methods to find/replace missing values
Etc.
Objects#
You can make multiple objects of the same type and they will have their own, independent state. For example, in the next cell, we make two pandas.DataFrame that happen to have the same state, but they are two completely different objects!
import pandas as pd
# Create two, independent DataFrame objects
df1 = pd.DataFrame({'a': [1,2,3]})
df2 = pd.DataFrame({'a': [1,2,3]})
# Print both out
print('df1 Before Change')
print(df1)
print()
print('df2 Before Change')
print(df2)
print()
# Only modify df1
df1.loc[1, 'a'] = 14
# Print both out
print('df1 After Change')
print(df1)
print()
print('df2 After Change')
print(df2)
print()
Both df1 and df2 refer to completely different objects so updating one will not update the other! This is similar to having two different people, who happen to be wearing identical shirts. Just because they have shirts that look the same, they are still two different people!
References#
When thinking about objects, it’s important that we have a correct idea of the memory model of our program. A memory model is a visual description of how these objects relate to each other. For the last code cell above, the memory model of these objects should look like the following:
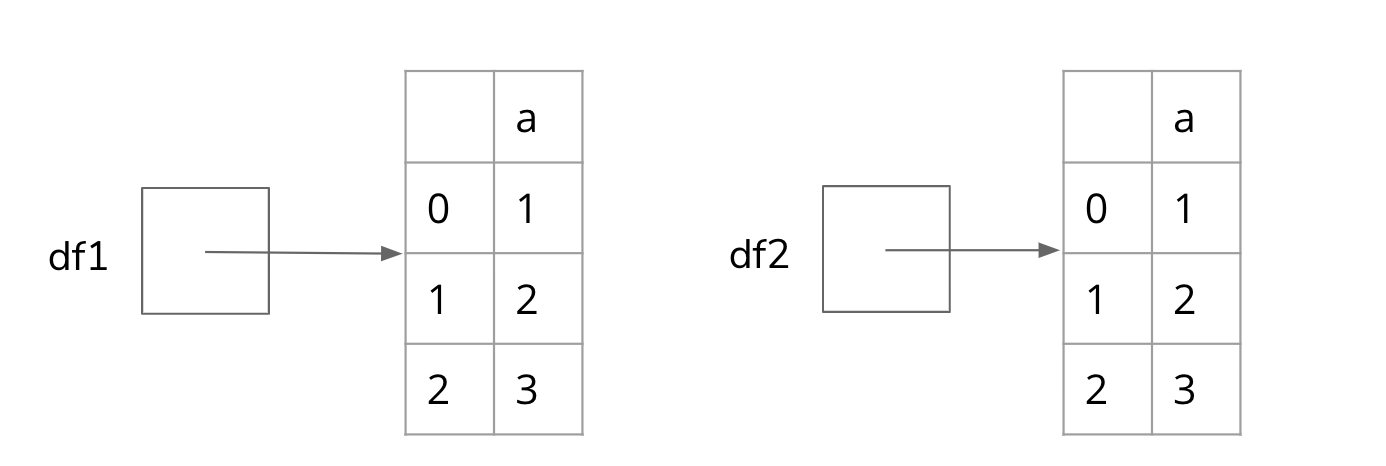
In this program, we have two variables df1 and df2 and two pandas.DataFrame objects that contain the same sequence of values. This memory model highlights the fact we stated earlier that these two DataFrame s are completely separate objects that happen to have the same values. This is just like how two people can have the same name and same age, but are still two distinct human beings.
It’s important to emphasize that in this drawing, the DataFrame objects are not inside the variables df1 and df2 . This is because Python stores references to the DataFrame s in the variables rather than the DataFrame itself. You should think of references as phone numbers. df1 stores the phone number to call the DataFrame on the left.
Why is this distinction important? See the following code cell.
import pandas as pd
df1 = pd.DataFrame({'a': [1,2,3]})
df2 = pd.DataFrame({'a': [1,2,3]})
df3 = df1
Now we will ask a simple question with potentially a surprising result:
How many
DataFrameobjects exist in this program? Is the answer 3? Is it 2?
It turns out there are only two DataFrame objects in this program! If we draw out the memory model after this program has run its 5 lines, it would look like the following.
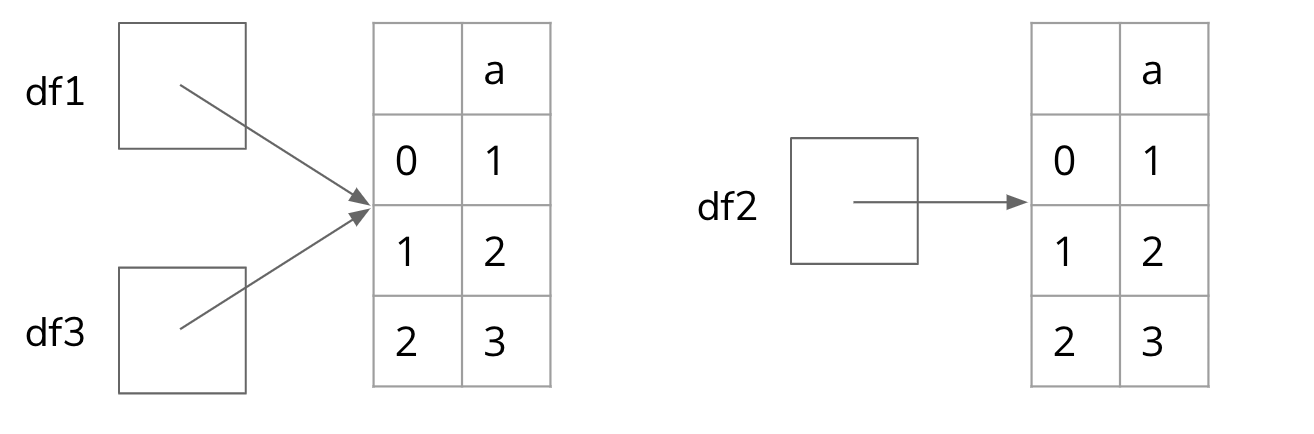
This is why it’s so important that we are careful about distinguishing between an object and a reference to an object . When we write df3 = df1 , it does NOT make a new DataFrame , but rather makes a new variable df3 that stores the same reference as df1 .
Go back to the phone number analogy. This scenario is like if I had Madrona’s phone number in a variable labeled phone1 (you could say that phone1 has a way of referring to Madrona). What should happen if I shared Madrona’s phone number with Wen? She would write the phone number stored in my phone1 variable into her own variable, phone2 so she could refer to Madrona later. Would we expect that another copy of Madrona now exists in the world? No! We just have two ways to call the same person.
How does this have an impact on the code you write? Well if we run the same code cell, but now modify df1 , we will see the change in df3 too (since they refer to the same object!).
import pandas as pd
df1 = pd.DataFrame({'a': [1,2,3]})
df2 = pd.DataFrame({'a': [1,2,3]})
df3 = df1
# Print both out
print('df1 Before Change')
print(df1)
print()
print('df2 Before Change')
print(df2)
print()
print('df3 Before Change')
print(df3)
print()
# Only modify df1
df1.loc[1, 'a'] = 14
# Print both out
print('df1 After Change')
print(df1)
print()
print('df2 After Change')
print(df2)
print()
print('df3 After Change')
print(df3)
print()
Why did we see the change in df3 ? When we say df1.loc[0, 'a'] = 14 we are “calling up” the phone number and changing the state of the object!
Recall: Methods Returning New Objects#
Recall when we call methods on str they will always return new str objects because the str is immutable. Additionally, DataFrame and Series functions generally return new DataFrame s and Series as a convention rather than modifying the object (even though they are mutable and there are ways of mutating their state).
Thinking about this memory model, this means when you call something like df.dropna() , this method creates a new DataFrame that stores the same state (rows/cols) as df but with all the NaN rows missing. The fact it creates a new DataFrame is precisely why the original df wasn’t modified. For example, consider the following snippet. By the end of this program, there will be 2 variables storing references to 2 different DataFrame objects.
import numpy as np # For NaN
import pandas as pd
df = pd.DataFrame({'a': [1, np.nan, 3]})
df2 = df.dropna()
print('df')
print(df)
print()
print('df2')
print(df2)
Identity#
Thinking back to one of our earlier snippets, shown below, we can show another example to understand more concretely this notion of a reference to an object.
import pandas as pd
df1 = pd.DataFrame({'a': [1,2,3]})
df2 = pd.DataFrame({'a': [1,2,3]})
df3 = df1
Python has a built-in function called id that lets you see this internal “phone number” to an object that is stored inside the variables. As a note, you will never use this id function in practice (explained next time), but it helps to see how this all works.
import pandas as pd
df1 = pd.DataFrame({'a': [1,2,3]})
df2 = pd.DataFrame({'a': [1,2,3]})
df3 = df1
print('df1:', id(df1))
print('df2:', id(df2))
print('df3:', id(df3))
Notice that this id function returns this “phone number” and the values for df1 and df3 are the same while the one for df2 is different. This tells us that df1 and df3 are actually variables referencing the same object since they both store this same phone number.
Note
If you’re curious, for most implementations of Python, this “phone number” is actually a number describing the location of the object in your computer’s memory. In a later lesson, we will talk about how your computer’s memory is like a big array where you can write data, and this “phone number” is precisely the location of this object in your computer’s memory.